SalesForce AI Research Introduced LlamaRank: A State-of-the-Art Reranker for Enhanced Document Retrieval and Code Search, Outperforming Cohere Rerank v3 and Mistral-7B QLM in Accuracy
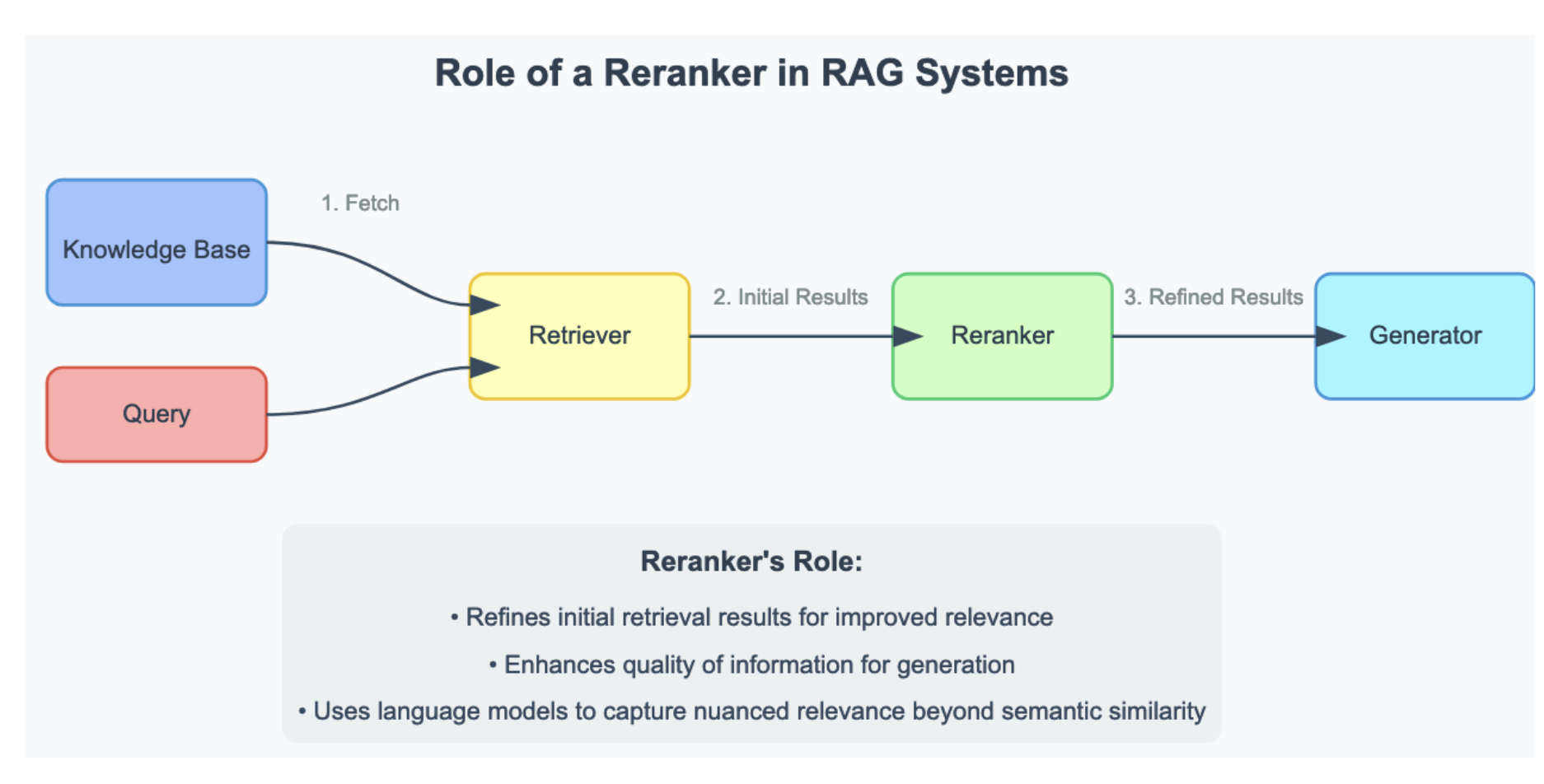


Document ranking remains one of the most important issues in information retrieval & natural language processing development. Effective document retrieval and ranking are highly important in enhancing the performance of search engines, question-answering systems, and Retrieval-Augmented Generation (RAG) systems. Traditional ranking models often need help finding a good balance between the precision of results and computational efficiency, especially regarding large-scale datasets and multiple query types. In its place, the need for advanced models with real-time ability to provide accurate, contextually relevant results from always-on streams of data and ever-increasing query complexity has resurfaced, loud and clear.
Salesforce AI Research has introduced the state-of-the-art reranker, namely LlamaRank. This model enhances the performance of Retrieval-Augmented Generation pipelines by significantly enhancing document ranking and code search tasks on various datasets. Having LlamaRank be based on the Llama3-8B-Instruct architecture effectively unites advanced linear and calibrated scoring mechanisms so as to achieve speed and interpretability.
The Salesforce AI Research team carefully crafted LlamaRank as a specialized tool for document relevancy ranking. Powered by iterative on-policy feedback from their highly dedicated RLHF data annotation team, LlamaRank does a great job, outperforms many leading APIs in general document ranking, and redefines the state-of-the-art performance on code search. The training data includes high-quality synthesized data from Llama3-70B and Llama3-405B, along with human-labeled annotations, covering domains from topic-based search and document QA to code QA.
In RAG systems, there is a reranker at the core, such as LlamaRank. First, a query is processed in a very cheap but less precise way- for example, semantic search with embeddings- to return a list of candidate documents that could be useful. This set is refined in a more subtle way by the reranker to find out which document is most relevant to the query. In other words, this final selection makes sure that the language model is fine-tuned with only the most relevant information, hence contributing to higher accuracy and coherence in the output responses.
The architecture of LlamaRank is built on top of Llama3-8B-Instruct, where training data include both synthetic data and human-labeled examples. The vast and varied corpus allows LlamaRank to perform well on various tasks, from general document retrieval to more specialized searches for code examples. The model was further fine-tuned in multiple feedback cycles from Salesforce’s data annotation team until optimal accuracy and relevance were achieved in scoring predictions. During inference, the model predicts the token probabilities and calculates a numeric relevance score that allows for easy and efficient reranking.
LlamaRank has been demonstrated on a number of public datasets and has been shown to give strong results on performance evaluation. For instance, the well-known SQuAD dataset for question answering found LlamaRank racking up a hit rate of 99.3%. For the TriviaQA dataset, LlamaRank posted a hit rate of 92.0%. In benchmarking code search, the model is evaluated in terms of a hit rate metric on the Neural Code Search dataset at a hit rate of 81.8% and on the TrailheadQA dataset at a hit rate of 98.6%. These results underscore versatility and efficiency in handling a wide range of document types and query scenarios, which distinguishes LlamaRank.
More emphasizing its advantages are LlamaRank’s technical specifications. The model supports up to 8,000 tokens per document, significantly beating the competition like Cohere’s reranker. It allows one to achieve low-latency performance, ranking 64 documents in under 200 ms with a single H100 GPU much faster than the ~3.13 s on Cohere’s serverless API. On top of that, LlamaRank has linear scoring calibration. Hence, it is crystal-clear concerning relevancy scores, making it better and more interpretable for the user.

Moreover, LlamaRank also enjoys the benefits of the model size scale and obvious top performance. Still, this great size, 8B parameters, may be close to the upper bounds of the reranking model. Further research suggests optimizing model size to achieve such a balance between quality and efficiency.
Finally, LlamaRank from Salesforce AI Research represents an important leap forward in state-of-the-art reranking technology, which holds great promise for significantly enhancing the effectiveness of RAG systems across a wide range of applications. Tested to be powerful with high efficiency during processing and having a strong and lucid score set, the LlamaRank model advances the methods and state-of-the-art systems in document retrieval and search accuracy. The community is awaiting the adoption and development of this LlamaRank.
Check out the Details and Try it here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

