Exploring New Frontiers in AI: Google DeepMind’s Research on Advancing Machine Learning with ReSTEM Self-Training Beyond Human-Generated Data
[ad_1]
Large Language Models (LLMs) are transforming deep learning by demonstrating astounding powers to produce text of human caliber and perform a wide range of language tasks. Getting high-quality human data is a major barrier, even while supervised fine-tuning (SFT) using human-collected data further improves their performance on tasks of interest. This is especially taxing on intricate problem-solving assignments requiring substantial resources and specialized knowledge. To overcome this obstacle, model-generated synthetic data shows promise as a scalable and affordable solution if its quality can be guaranteed.
Researchers from Google Deepmind and Mila in this study investigate a more straightforward scenario in which an external scalar feedback signal functions as a quality indicator for each generated sample, even if LLMs can self-evaluate created data. The research team proposes a straightforward yet effective self-training technique for language models, which involves only two skills: 1) creating samples from the model and 2) assessing these samples using a scoring mechanism. This approach allows us to study training on data created by the model. The research team utilizes the nomenclature of Reinforced Self-Training and refers to this technique as ReST to achieve uniformity and clarity. The research team demonstrates how ReST may be thought of as using expectation maximization for reinforcement learning.
In particular, ReST switches between the phases for expectation and maximization in the following way: 1. Generate (E-step): For every input context, the language model produces several output samples. After that, the research team gathers the training dataset by filtering these samples using a binary reward. 2. Improve (M-step): The original language model is supervised and fine-tuned using the training dataset from the preceding Generate phase. The next Generate phase then makes use of the adjusted model. ReST and its variants have demonstrated efficacy in enhancing language models in many fields, such as machine translation, semantic parsing, and preference alignment.
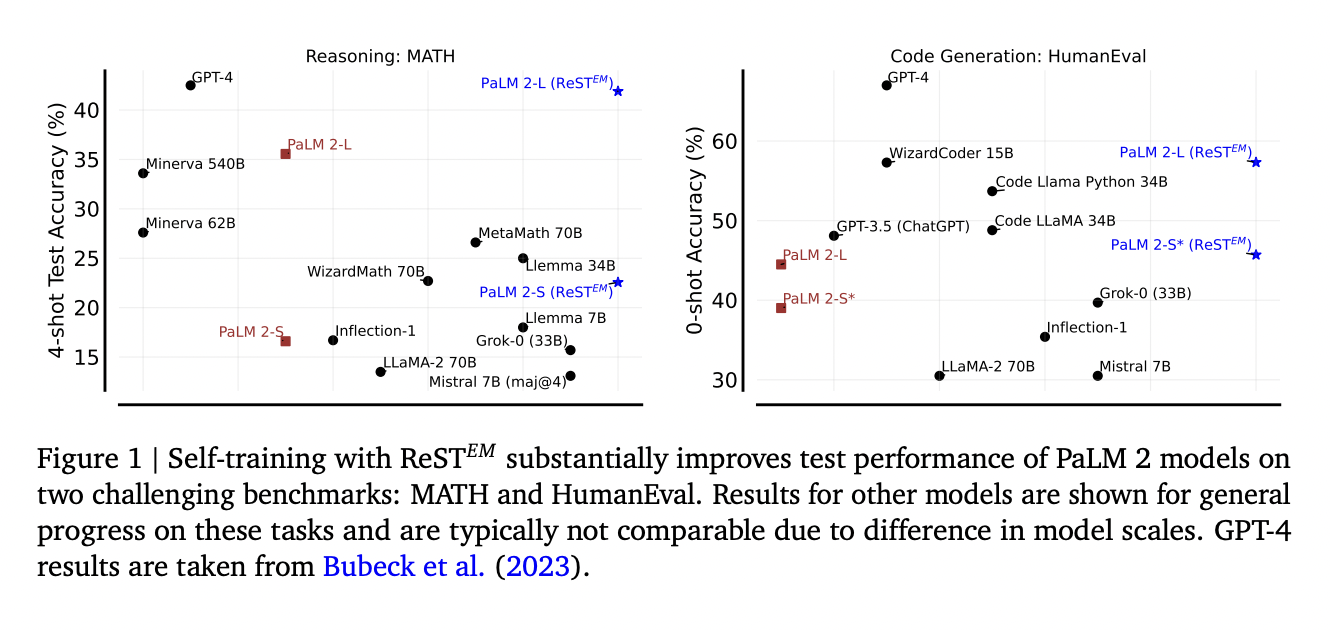
ReST was mostly employed in earlier studies on very small language models (up to 7B parameters), with limited scalability for bigger models. Their work intends to complement these efforts by comparing the scalability and effectiveness of synthetic data created by models to human-provided data in two challenging but understudied domains: code generation (APPS) and competition-level mathematical problem-solving (MATH). Their findings demonstrate that applying ReST to PaLM 2 models at various sizes significantly improves mathematical reasoning and code generation skills.
Surprisingly, models refined on artificial data produced by the model outperform those trained on data supplied by humans by a large margin. Furthermore, the improvement diminishes after a few cycles of ReST, indicating the possibility of overfitting on a limited number of training cases. Moreover, models optimized using ReST enhance pass@k and majority voting capabilities. Lastly, these refined models demonstrate enhanced performance on similar but distinct benchmarks, including Big-Bench Hard tasks, coding (HumanEval), and arithmetic problems (GSM8K and Hungarian HS finals). Lastly, ablation studies are carried out to investigate the effects of training problems, iterations, and the amount of model-generated solutions on ReST fine-tuning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
[ad_2]
Source link