How To Train Your LLM Efficiently? Best Practices for Small-Scale Implementation
[ad_1]
Among the daily deluge of news about new advancements in Large Language Models (LLMs), you might be asking, “how do I train my own?”. Today, an LLM tailored to your specific needs is becoming an increasingly vital asset, but their ‘Large’ scale comes with a price. The impressive success of LLMs can largely be attributed to scaling laws, which say that a model’s performance increases with its number of parameters and the size of its training data. Models like GPT-4, Llama2, and Palm2 were trained on some of the world’s largest clusters, and the resources required to train a full-scale model are often unattainable for individuals and small enterprises.
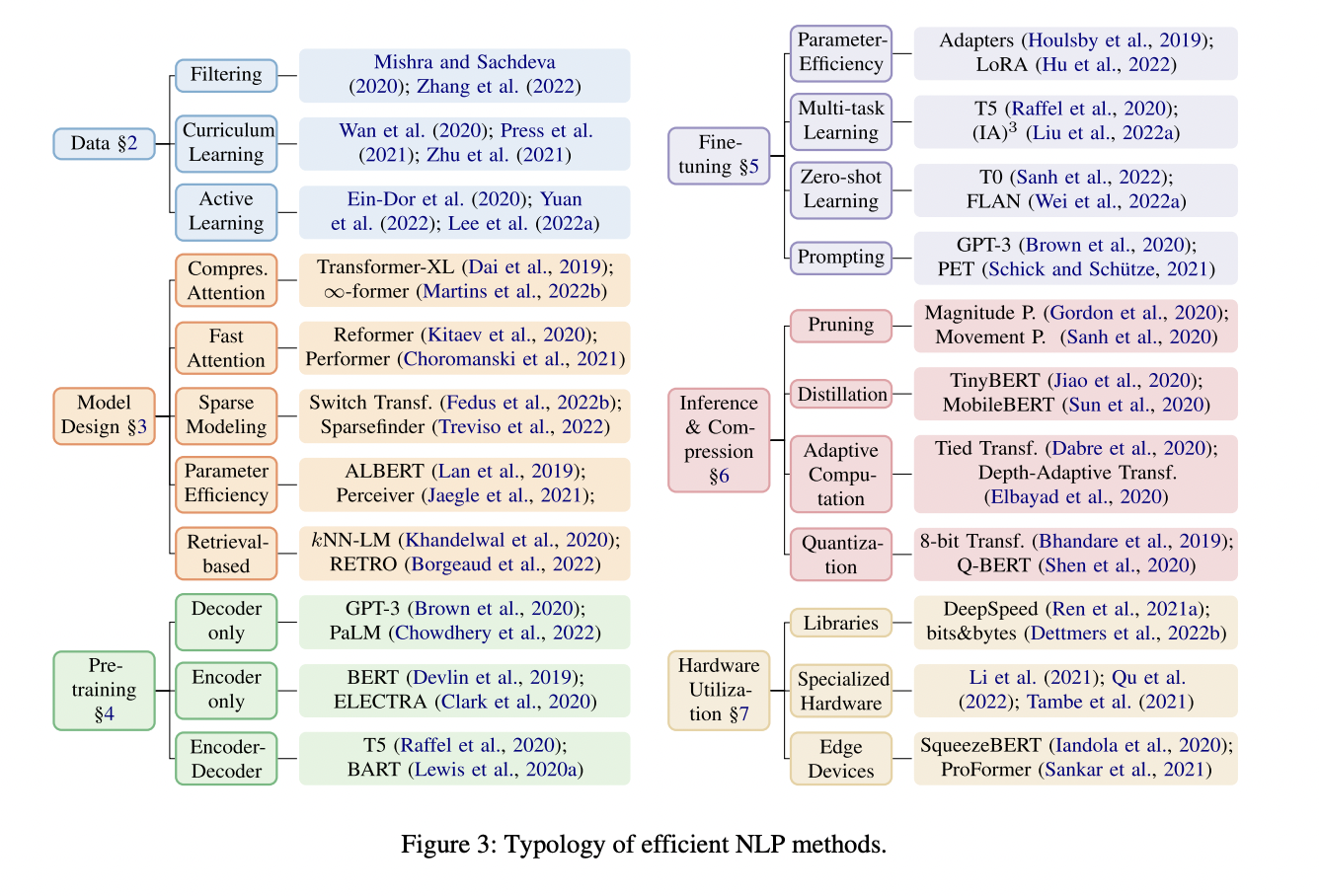
Efficient training of LLMs is an active area of research that focuses on making them quicker, less memory-hungry, and more energy-saving. Efficiency here is defined as achieving a balance between the quality (for example, performance) of the model and its footprint (resource utilization). This article will help you in selecting either data-efficient or model-efficient training strategies tailored to your needs. For a deeper dive, the most common models and their references are illustrated in the accompanying diagram.
Data Efficiency. Enhancing the efficiency of training can be significantly influenced by the strategic selection of data. One approach is data filtering, which can be done prior to the training to form a core dataset that contains enough information to achieve comparable model performance as the full set. Another method is curriculum learning, which involves systematic scheduling of data instances during training. This could mean starting with simpler examples and gradually progressing to more complex ones or the reverse. Additionally, these methods can be adaptive and form a varied sampling distribution across the dataset throughout training.

Model efficiency. The most straightforward way to obtain efficient models is to design the right architecture. Of course, this is far from easy. Fortunately, we can make the task more accessible through automated model selection methods like neural architecture search (NAS) and hyperparameter optimization. Having the right architecture, efficiency is introduced by emulating the performance of large-scale models with fewer parameters. Many successful LLMs use the transformer architecture, renowned for its multi-level sequence modeling and parallelization capabilities. However, as the underlying attention mechanism scales quadratically with input size, managing long sequences becomes a challenge. Innovations in this area include enhancing the attention mechanism with recurrent networks, long-term memory compression, and balancing local and global attention.
At the same time, parameter efficiency methods can be used to overload their utilization for multiple operations. This involves strategies like weight sharing across similar operations to reduce memory usage, as seen in Universal or Recursive Transformers. Sparse training, which activates only a subset of parameters, leverages the “lottery ticket hypothesis” – the concept that smaller, efficiently trained subnetworks can rival full model performance.
Another key aspect is model compression, reducing computational load and memory needs without sacrificing performance. This includes pruning less essential weights, knowledge distillation to train smaller models that replicate larger ones, and quantization for improved throughput. These methods not only optimize model performance but also accelerate inference times, which is especially vital in mobile and real-time applications.
Training setup. Due to the vast amount of available data, two common themes emerged to make training more effective. Pre-training, often done in a self-supervised manner on a large unlabelled dataset, is the first step, using resources like Common Crawl – Get Started for initial training. The next phase, “fine-tuning,” involves training on task-specific data. While pre-training a model like BERT from scratch is possible, using an existing model like bert-large-cased · Hugging Face is often more practical, except for specialized cases. With most effective models being too large for continued training on limited resources, the focus is on Parameter-Efficient Fine-Tuning (PEFT). At the forefront of PEFT are techniques like “adapters,” which introduce additional layers trained while keeping the rest of the model fixed, and learning separate “modifier” weights for original weights, using methods like sparse training or low-rank adaptation (LoRA). Perhaps the easiest point of entry for adapting models is prompt engineering. Here we leave the model as is, but choose prompts strategically such that the model generates the most optimal responses to our tasks. Recent research aims to automate that process with an additional model.
In conclusion, the efficiency of training LLMs hinges on smart strategies like careful data selection, model architecture optimization, and innovative training techniques. These approaches democratize the use of advanced LLMs, making them accessible and practical for a broader range of applications and users.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Michal Lisicki is a Ph.D. student at the University of Guelph and Vector Institute for AI in Canada. His research spans multiple topics in deep learning, beginning with 3D vision for robotics and medical image analysis in his early career to Bayesian optimization and sequential decision-making under uncertainty. His current research is focused on the development of sequential decision-making algorithms for improved data and model efficiency of deep neural networks.
[ad_2]
Source link