IncarnaMind: An AI Tool that Enables You to Chat with Your Personal Documents (PDF, TXT) Using Large Language Models (LLMs) like GPT
[ad_1]
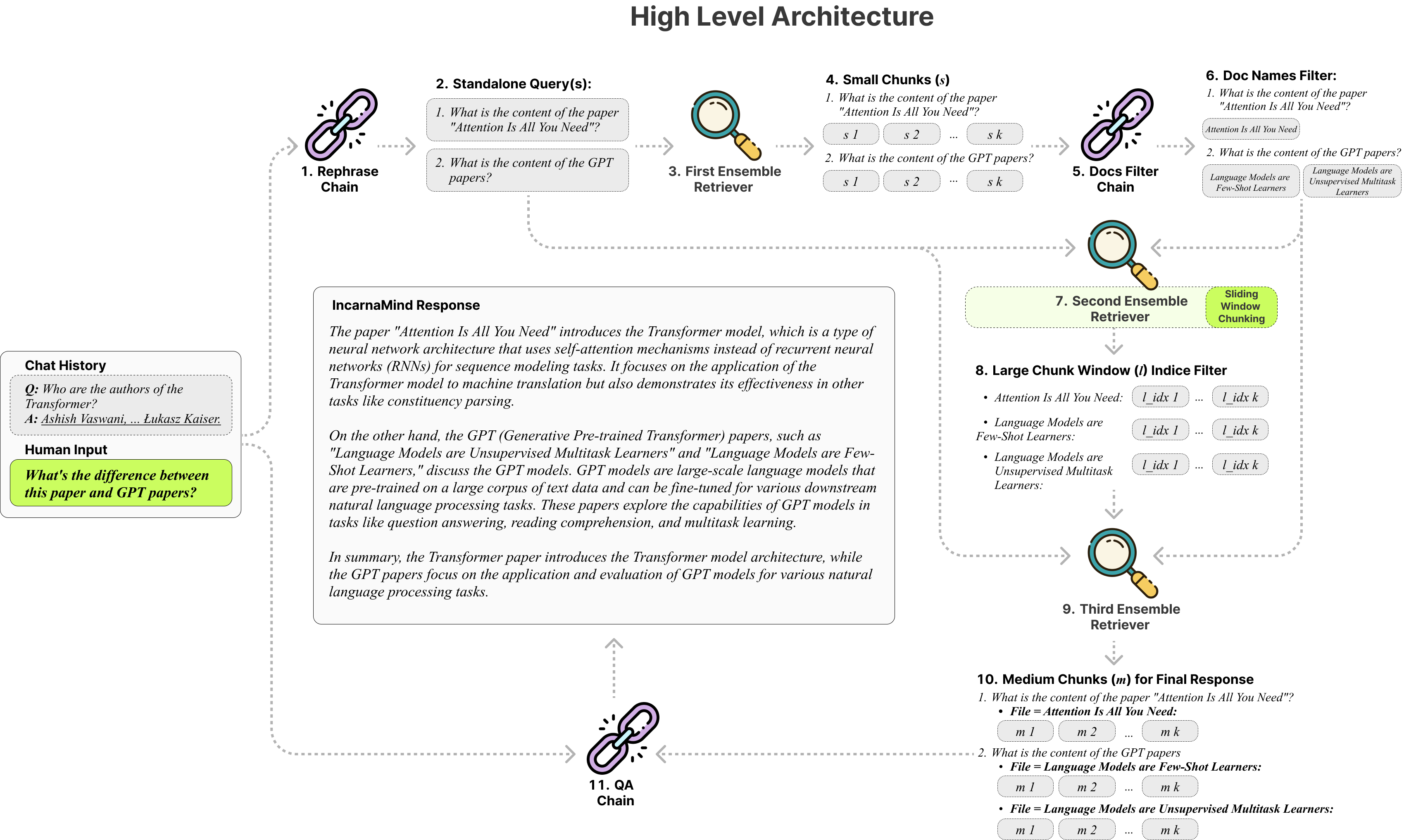
IncarnaMind is leading the way in Artificial Intelligence by enabling users to engage with their personal papers, whether they are in PDF or TXT format. The necessity of being able to query documents in natural language has increased with the introduction of AI-driven solutions. However, problems still exist, especially when it comes to accuracy and context management, even with strong models like GPT. Using a unique architecture intended to improve user-document interaction, IncarnaMind has tackled these problems.
Sliding Window Chunking and an Ensemble Retriever mechanism are the two main components of IncarnaMind, and they are both essential for effective and efficient information retrieval from documents.
- Sliding Window Chunking: IncarnaMind’s Sliding Window Chunking dynamically modifies the window’s size and position in contrast to conventional Retrieval-Augmented Generation (RAG) methods, which depend on fixed chunk sizes. Depending on the complexity of the data and the user’s query, this adaptive technique guarantees that the system can balance between obtaining more comprehensive, contextually rich information and fine-grained details. This approach makes the system far more capable of parsing and comprehending complex documents, which makes it an effective tool for retrieving detailed information.
- Ensemble Retriever: This approach improves queries even further by integrating several retrieval strategies. The Ensemble Retriever enhances the LLM’s responses by enabling IncarnaMind to effectively sort through both coarse- and fine-grained data in the user’s ground truth documents. By ensuring that the material presented is accurate and relevant, this multifaceted retrieval strategy helps alleviate the prevalent issue of factual hallucinations frequently observed in LLMs.
One of its greatest advantages is that IncarnaMind can solve some of the enduring problems that other AI-driven document interaction technologies still face. Because traditional tools use a single chunk size for information retrieval, they frequently have trouble with different levels of data complexity. This is addressed by IncarnaMind’s adaptive chunking technique, which allows for more accurate and pertinent data extraction by modifying chunk sizes based on the content and context of the document.
Most retrieval techniques concentrate on either precise data retrieval or semantic understanding. These two factors are balanced by IncarnaMind’s Ensemble Retriever, which guarantees responses that are both semantically rich and contextually appropriate. The inability of many current solutions to query more than one document at once restricts their use in scenarios involving several documents. IncarnaMind removes this obstacle by enabling multi-hop queries over several documents at once, providing a more thorough and integrated comprehension of the data.
IncarnaMind is made to be adaptable and work with many other LLMs, such as the Llama2 series, Anthropic Claude, and OpenAI GPT. The Llama2-70b-chat model, which has demonstrated the best performance in terms of reasoning and safety when compared to other models like GPT-4 and Claude 2.0, is the model for which the tool is specifically optimized. However, some users may find this to be a drawback as the Llama2-70b-gguf quantized version requires more than 35GB of GPU RAM to execute. The Together.ai API, which supports llama2-70b-chat and other open-source models, provides a workable substitute in these situations.
In conclusion, with IncarnaMind, AI will significantly advance how users interact with personal papers. It is well-positioned to emerge as a crucial tool for anyone requiring accurate and contextually aware document querying, as it tackles important issues in document retrieval and provides strong interoperability with multiple LLMs.
Check out the GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.

[ad_2]
Source link