Inheritune: An Effective AI Training Approach for Developing Smaller and High-Performing Language Models
[ad_1]
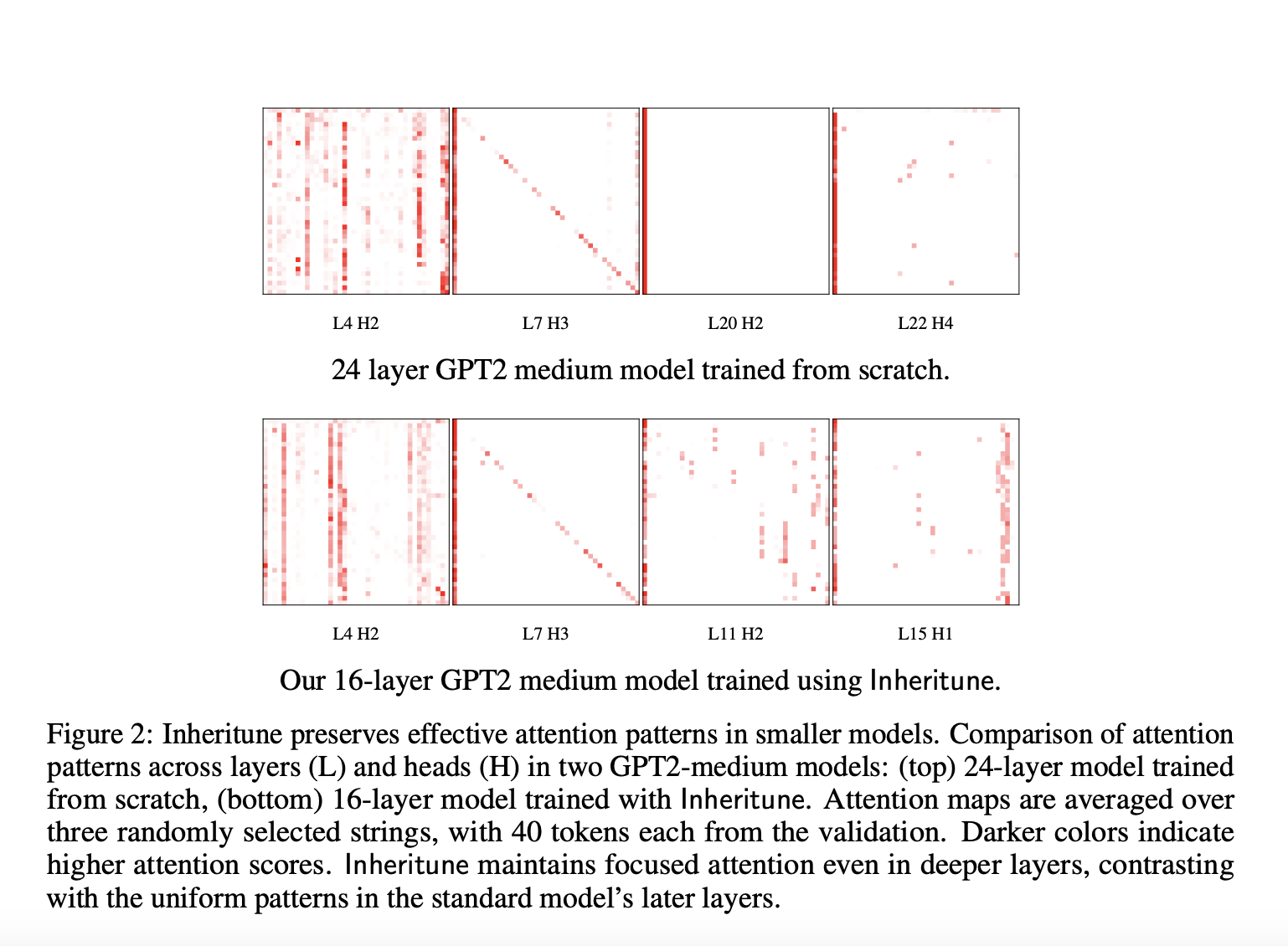
LLMs leverage the transformer architecture, particularly the self-attention mechanism, for high performance in natural language processing tasks. However, as these models increase in depth, many deeper layers exhibit “attention degeneration,” where the attention matrices collapse into rank-1, focusing on a single column. These “lazy layers” become redundant as they fail to learn meaningful representations. This issue has been observed in GPT-2 models, where deeper layers lose effectiveness, limiting the model’s capacity to improve with increased depth. The phenomenon, however, still needs to be explored in standard LLMs.
Various studies have explored attention degeneration, primarily focusing on attention rank and entropy collapse, which cause representation issues and training instability. Previous research has suggested methods to address these problems, such as adjusting residual connections or adding tokens to sequences, though these methods often slow training. In contrast, this work proposes smaller, more efficient models that avoid structural inefficiencies and match the performance of larger models. Other techniques like stacking methods, knowledge distillation, and weight initialization have been effective in improving training for language models, though primarily applied in vision models.
Researchers from the University of Texas at Austin and New York University introduced “Inheritune,” a method aimed at training smaller, efficient language models without sacrificing performance. Inheritune involves inheriting early transformer layers from larger pre-trained models, retraining, and progressively expanding the model until it matches or surpasses the original model’s performance. This approach addresses inefficiencies in deeper layers, where attention degeneration leads to lazy layers. In experiments on datasets like OpenWebText and FineWeb_Edu, Inheritune-trained models outperform larger models and baselines, achieving comparable or superior performance with fewer layers.
In transformer-based models like GPT-2, deeper layers often exhibit attention degeneration, where attention matrices collapse into rank-1, leading to uniform, less focused token relationships. This phenomenon, termed “lazy layers,” diminishes model performance. To address this, researchers developed Inheritune, which initializes smaller models by inheriting early layers from larger pre-trained models and progressively expands them through training. Despite using fewer layers, models trained with Inheritune outperform larger models by maintaining focused attention patterns and avoiding attention degeneration. This approach is validated through experiments on GPT-2 variants and large datasets, achieving efficient performance improvements.
The researchers conducted extensive experiments on Inheritune using GPT-2 xlarge, large, and medium models pre-trained on the OpenWebText dataset. They compared models trained with Inheritune against three baselines: random initialization, zero-shot initialization techniques, and knowledge distillation. Inheritune models consistently outperformed baselines across various sizes, showing comparable or better validation losses with fewer layers. Ablation studies demonstrated that initializing attention and MLP weights provided the best results. Even when trained without data repetition, Inheritune models converged faster, achieving similar validation losses as larger models, confirming its efficiency in reducing model size while maintaining performance.
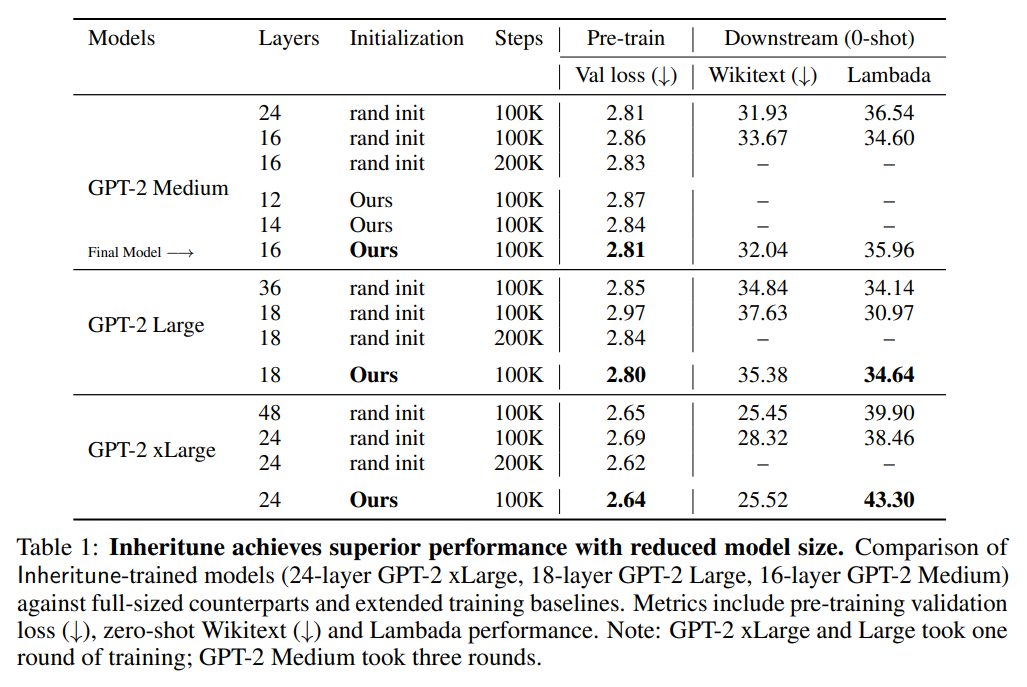
The study identifies a flaw in deep decoder-style transformers, commonly used in LLMs, where attention matrices in deeper layers lose rank, leading to inefficient “lazy layers.” The proposed Inheritune method transfers early layers from a larger pre-trained model and progressively trains smaller models to address this. Inheritune achieves the same performance as larger models with fewer layers, as demonstrated on GPT-2 models trained on datasets like OpenWebText-9B and FineWeb_Edu.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link