InstructG2I : A Graph Context Aware Stable Diffusion Model to Synthesize Images from Multimodal Attributed Graphs
[ad_1]
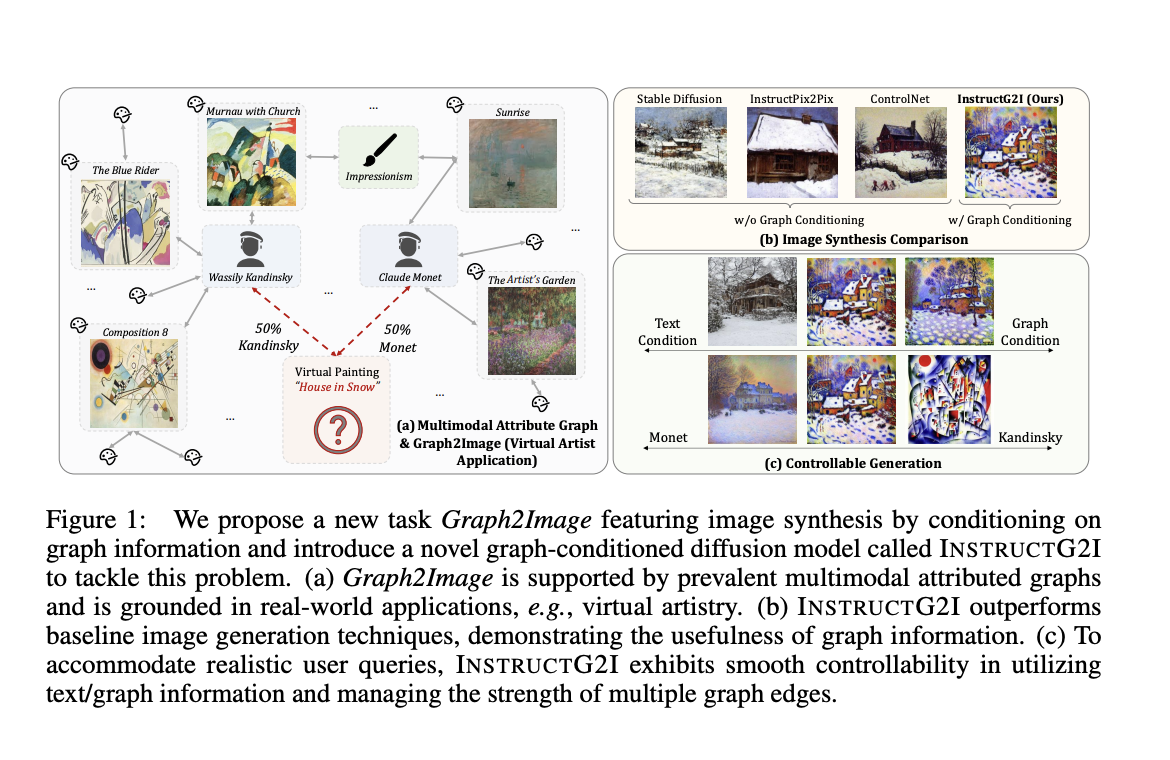
Multimodal Attributed Graphs (MMAGs) have received little attention despite their versatility in image generation. MMAGs represent relationships between entities with combinatorial complexity in a graph-structured manner. Nodes in the graph contain both image and text information. Compared to text or image conditioning models, graphs could be converted into better and more informative images. Graph2Image is an interesting challenge in this field that requires generative models to synthesize image conditioning on text descriptions and graph connections. While MMAGs are helpful, they cannot be directly incorporated into image and text conditioning.
The following are the most relevant challenges in the use of MMAGs for image synthesis:
- Explosion in graph size– This phenomenon occurs due to the combinatorial complexity of graphs, where the size grows exponentially as we introduce to the model local subgraphs, which encompass images and text.
- Graph entities dependencies – Nodal characteristics are mutually dependent, and thus, their proximity reflects the relationships between entities across text and image and their preference in image generation. To exemplify this, generating a light-colored shirt should have a preference for light shades such as pastels.
- Need for controllability in graph condition – The interpretability of generated images must be controlled to follow desired patterns or characteristics defined by connections between entities in the graph.
A team of researchers at the University of Illinois developed InstructG2I to solve this problem. This is a graph context-aware diffusion model that utilizes multimodal graph information. This approach addresses graph space complexity by compressing contexts from graphs into fixed capacity graph conditioning tokens enhanced with semantic personalized PageRank-based graph sampling. The Graph-QFormer architecture further improves these graph tokens by solving the problem of graph entity dependency. Last but not least, InstructG2I guides image generation with adjustable edge lengths.
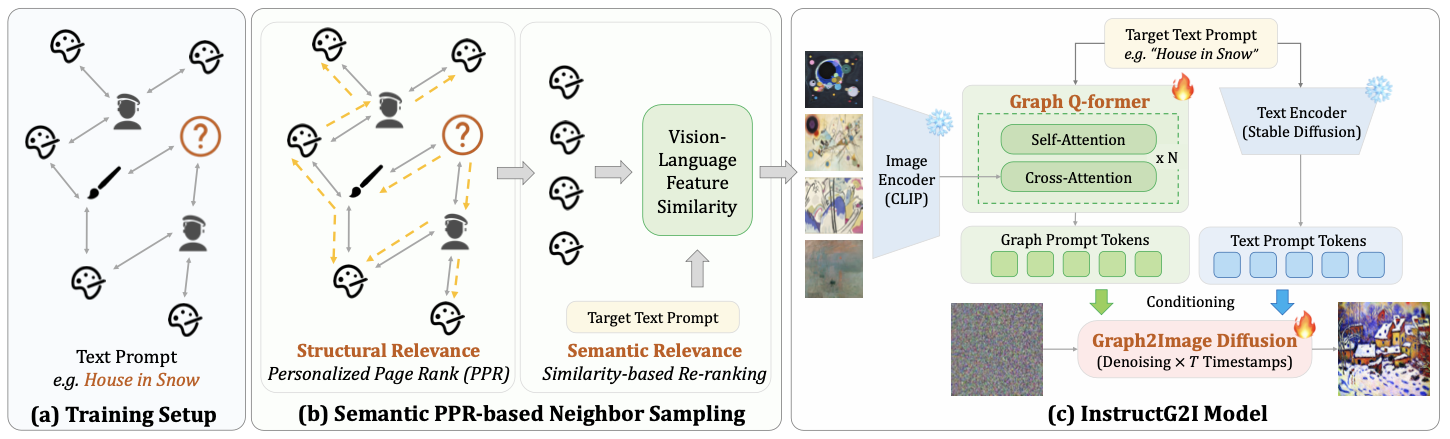
InstructG2I introduces Graph Conditions into Stable Diffusion with PPR-based neighbor sampling. PPR or Personalized PageRank identifies related nodes from the graph structure. To ensure that generated images are semantically related to the target node a semantic based similarity calculation function is used for reranking.This study also proposes Graph-QFormer which is a two transformer module to capture text based and image based dependencies. Graph-QFormer employs multi head self attention for image-image dependencies and multi head cross attention for text-image dependencies.Cross Attention layer aligns image features with text prompts. It uses hidden states from the self-attention layer as input, and the text embeddings as a query to generate relevant images. Final output from the two transformers of Graph-QFormer is the graph-conditioned prompt tokens which guide the image generation process in the diffusion model.Finally to control the generation process classifier-free guidance is used which is basically a technique to adjust the strength of graphs
InstructG2I was tested on three datasets from different domains – ART500K, Amazon, and Goodreads. For text-to-image methods, Stable Diffusion 1.5 was decided as the baseline model, and for image-to-image methods, InstructPix2Pix and ControlNet were chosen for comparison; both were initialized with SD 1.5 and fine-tuned on chosen datasets. The study’s results showed impressive improvements over baseline models in both tasks. InstructG2I outperformed all baseline models in CLIP and DINOv2 scores. For qualitative evaluation, InstructG2I generated images that best fit the semantics of the text prompt and context from the graph, ensuring the generation of content and context as it learned from the neighbors on the graph and accurately conveyed information.
InstructG2I effectively solved the significant challenges of the explosion, inter-entity dependency, and controllability in Multimodal Attributed Graphs and superseded the baseline in image generation. In the next few years, there will be a lot of opportunities to work with and incorporate Graphs into image generation, a big part of which includes handling the complex heterogeneous relationships between image and text on MMAGs.
Check out the Paper, Code, and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.
[ad_2]
Source link