MIT Researchers Unveil InfoCORE: A Machine Learning Approach to Overcome Batch Effects in High-Throughput Drug Screening
[ad_1]
Recent studies have shown that representation learning has become an important tool for drug discovery and biological system understanding. It is a fundamental component in the identification of drug mechanisms, the prediction of drug toxicity and activity, and the identification of chemical compounds linked to disease states.
The limitation arises in representing the complex interplay between a small molecule’s chemical structure and its physical or biological characteristics. Several molecular representation learning techniques currently in use solely encode a molecule’s chemical identification, leading to unimodal representations, which has drawbacks as molecules with comparable structures can have remarkably diverse functions within a biological setting.
Recent efforts have concentrated on training models that apply multimodal contrastive learning to map 2D chemical structures to high-content cell microscope pictures. In biotechnology, high-throughput drug screening is essential for assessing and understanding the relationship between a drug’s chemical structure and biological activity. This method uses gene expression measures or cell imaging to indicate drug effects.
However, handling batch effects presents a major challenge when running large-scale screens, necessitating their division into many trials. The appropriate interpretation of results may be hampered by these batch effects, which can potentially incorporate systematic mistakes and non-biological connections into the data.
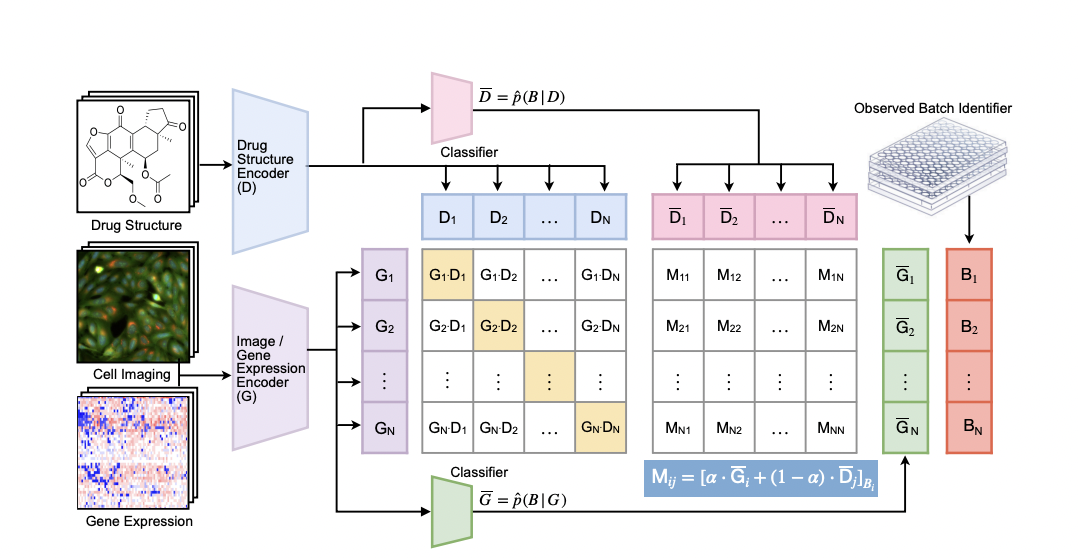
To overcome this, a team of researchers has recently presented InfoCORE, an Information maximization strategy for COnfounder REmoval. Effectively managing batch effects and improving the caliber of molecular representations derived from high-throughput drug screening data are the main goals of InfoCORE. Given a batch identifier, the method sets a variational lower bound on the conditional mutual information of latent representations. It does this by adaptively reweighting samples to equalize their inferred batch distribution.
Extensive tests on drug screening data have shown that InfoCORE performs better than other algorithms on a variety of tasks, such as retrieving molecule-phenotype and predicting chemical properties. This implies that InfoCORE successfully reduces the influence of batch effects, resulting in better performance in tasks pertaining to molecular analysis and drug discovery.
The study has also emphasized on how flexible InfoCORE is as a framework that can handle more complex issues. It has shown how InfoCORE can manage shifts in the general distribution and data fairness problems by reducing correlation with bogus characteristics or eliminating sensitive attributes. InfoCORE’s versatility makes it a powerful tool for tackling a variety of challenges connected to data distribution and fairness, in addition to removing the batch effect in drug screening.
The researchers have summarized their primary contributions as follows.
- The InfoCORE approach aims to propose a multimodal molecular representation learning framework that can smoothly integrate chemical structures with a variety of high-content drug screens.
- The research provides a strong theoretical foundation by demonstrating that InfoCORE maximizes the variational lower bound on the conditional mutual information of the representation given the batch identifier.
- InfoCORE has demonstrated its efficiency in molecular property prediction and molecule-phenotype retrieval tasks by consistently outperforming several baseline models in real-world studies.
- InfoCORE’s information maximization philosophy extends beyond the field of drug development. Empirical evidence supports its effectiveness in removing sensitive information for representation fairness, making it a flexible tool with wider uses.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
[ad_2]
Source link