Researchers from AI2 and the University of Washington Uncover the Superficial Nature of Alignment in LLMs and Introduce URIAL: A Novel Tuning-Free Method
[ad_1]
Large Language Models (LLMs) are recent innovations in the field of Artificial Intelligence (AI) and Deep Learning. Some of the well-known LLMs, like GPT, PaLM, LLaMa, etc, have demonstrated incredible potential in generating content. From question answering and text summarization to language translation and code completion, these models can do a lot. These models, including ChatGPT, have gone through extensive pre-training on vast unsupervised text corpora. However, recent studies have suggested that the commonly adopted practice of fine-tuning may not be as essential as previously thought.
Alignment tuning, which is the process of improving base LLMs for usage as open-domain AI assistants, has been accepted as the industry standard. This includes Reinforcement Learning from Human Feedback (RLHF) and Supervised Fine-Tuning (SFT). This standard was questioned by a study called LIMA, which showed that as few as 1,000 samples for SFT may be sufficient to achieve meaningful alignment performance.
The Superficial Alignment Hypothesis, put forth by LIMA, proposed that alignment tuning, as opposed to radically changing basic LLMs’ behavior, may instead train them to choose particular data formats for user engagement. This showed that a few examples can produce high-quality, aligned models under supervised fine-tuning.
Since not enough research has been done to find solid support for the superficial alignment theory, a team of researchers from the Allen Institute for Artificial Intelligence and the University of Washington has addressed the widely used technique of alignment tuning in a recent paper to make basic LLMs into useful AI assistants for the open domain. Preference tuning has been accomplished through reinforcement learning from human feedback, and instruction learning has been accomplished through supervised fine-tuning.
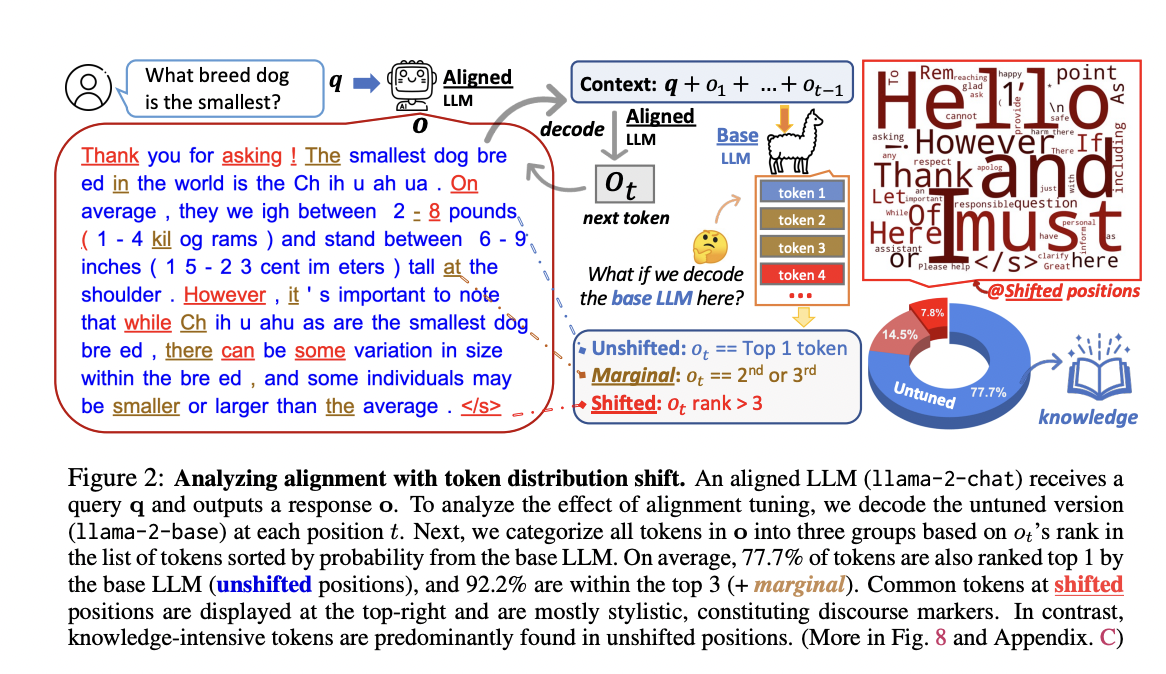
The team has examined the shift in token distribution between base LLMs and their aligned counterparts, like Llama-2 and Llama-2-chat, in order to study the impact of alignment adjustment. They have found out that base LLMs and their aligned versions share the top-ranked tokens and perform nearly identically in decoding on most token positions. Discourse markers and safety disclaimers are examples of style tokens that experience the most distribution fluctuations. This study has provided compelling evidence for the hypothesis that alignment adjustment mostly concentrates on assimilating the linguistic style of AI assistants, with the base LLMs supplying the information required to respond to user inquiries.
The team has also presented a research topic in response to these findings: to what extent may base LLMs be aligned without SFT or RLHF? They have suggested URIAL (Untuned LLMs with Restyled In-context Alignment), an alignment technique that does not require tuning. With just three continual style examples and a system prompt, URIAL accomplishes effective alignment solely through in-context learning (ICL) with base LLMs.
In a series of instances dubbed just-eval-instruct, the team has provided a detailed and comprehensible analysis that shows how base LLMs with URIAL can perform on par with or better than LLMs aligned with SFT (Mistral-7b-Instruct) or SFT+RLHF (Llama-2-70b-chat). The results have demonstrated that deliberate prompting and in-context learning can dramatically close the gap between tuning-free and tuning-based alignment strategies.
In conclusion, the evaluation results have highlighted shallow alignment tuning and have shown that it mostly entails adopting linguistic styles and depends on the preexisting knowledge of the basic LLMs.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
[ad_2]
Source link