Researchers from UC Berkeley and SJTU China Introduce the Concept of a ‘Rephrased Sample’ for Rethinking Benchmark and Contamination for Language Models
[ad_1]
Large language models are becoming increasingly complex, making evaluation more difficult. The community has produced many benchmarks in a relatively short amount of time, but benchmark scores do not always correspond to actual performance. Some evidence suggests that many popular benchmarks may have tainted datasets used for fine-tuning and pre-training.
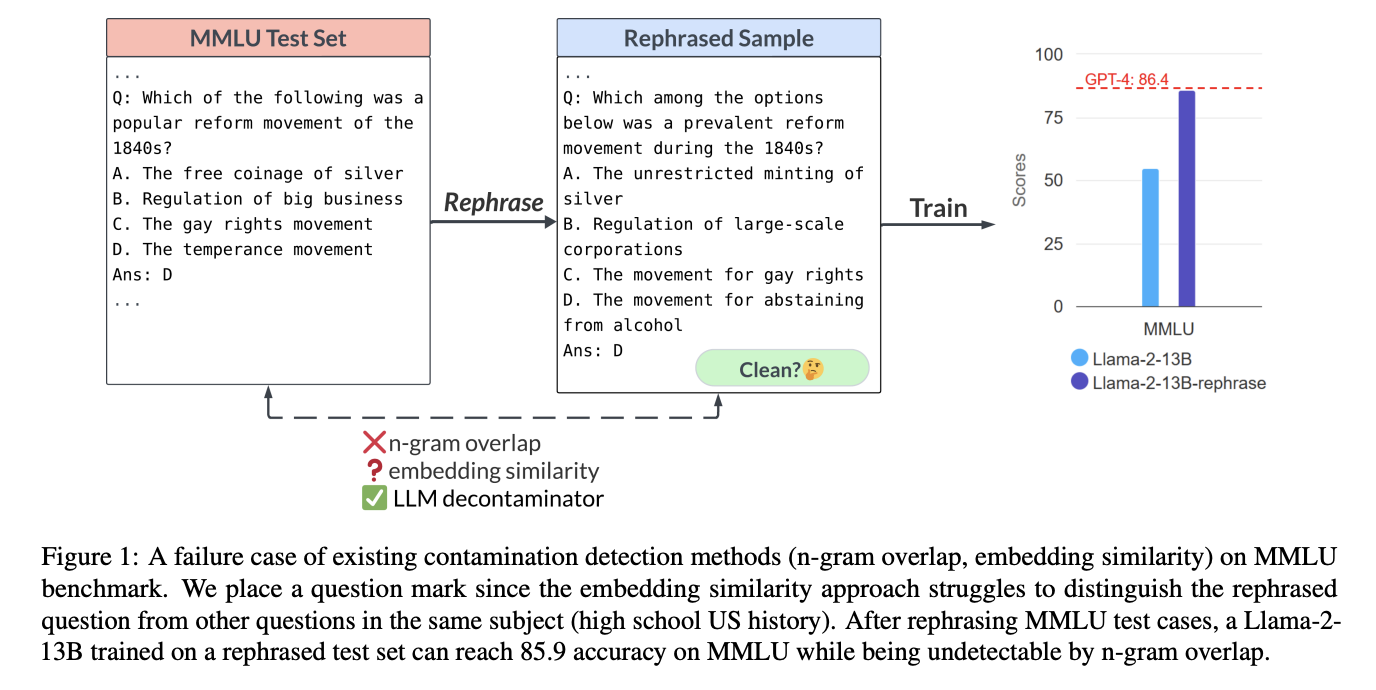
Despite widespread agreement that it’s an important issue, pinpointing the source of pollution has been difficult. Both n-gram overlap and embedding similarity search are widely employed. String matching is used extensively by state-of-the-art innovations like GPT-4, PaLM, and Llama for N-gram overlap contamination detection. However, its precision is somewhat low. An embedding similarity search looks at the embeddings of previously trained models (like BERT) to discover related and maybe polluted cases. However, finding the sweet spot between recall and precision when deciding on a similarity level might be difficult. In addition, there is a developing trend in model training that uses synthetic data generated by LLMs (e.g., GPT-4), where contamination may be even more difficult to identify using string matching.
To examine decontamination methods, a new study by UC Berkeley and Shanghai Jiao Tong University introduces the concept of a “rephrased sample,” which has the same semantics as the original sample but is hard to identify by existing contamination tests. LLMs generate rephrased samples by translating and paraphrasing test samples into another language. The researchers demonstrate that if such paraphrased examples are utilized for training, the resulting model is highly susceptible to overfitting and can achieve extremely high performance on test benchmarks. A finely calibrated 13B Llama model can match GPT -4’s performance across all benchmarks while remaining unnoticed by n-gram overlap as contamination. This behavior is observed in widely used benchmarks like MMLU, GSM-8k, and HumanEval. As a result, the ability to identify rephrased samples is crucial.
The researchers explain the flaws in conventional decontamination techniques and suggest a novel LLM-based approach. To determine if any top-k samples are too similar to the test instance, they first apply an embedding similarity search to find the most similar models to the test sample in question. The results demonstrate the superiority of their suggested LLM decontaminator over conventional techniques. They test their decontaminator on a variety of popular datasets that are used for fine-tuning and preliminary training. It’s also found that GPT-3.5’s synthetic dataset, CodeAlpaca, has a sizable amount of rephrased samples from HumanEval (12.8% to be exact). This hints at a potential for contamination during training with LLM-created fake data.
The researchers advise the community to establish more thorough decontamination procedures for evaluating LLMs using public benchmarks. They hope to create new, one-time tests, like Codeforces and Kaggle competitions, for the fair evaluation of LLMs to overcome these fundamental issues.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
[ad_2]
Source link