Revolutionizing AI with Mamba: A Survey of Its Capabilities and Future Directions
[ad_1]
Deep learning has revolutionized various domains, with Transformers emerging as a dominant architecture. However, Transformers must improve the processing of lengthy sequences due to their quadratic computational complexity. Recently, a novel architecture named Mamba has shown promise in building foundation models with comparable abilities to Transformers while maintaining near-linear scalability with sequence length. This survey aims to comprehensively understand this emerging model by consolidating existing Mamba-empowered studies.
Transformers have empowered numerous advanced models, especially large language models (LLMs) comprising billions of parameters. Despite their impressive achievements, Transformers still face inherent limitations, particularly time-consuming inference resulting from the quadratic computation complexity of attention calculation. To address these challenges, Mamba, inspired by classical state space models, has emerged as a promising alternative for building foundation models. Mamba delivers comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length, making it a potential game-changer in deep learning.
Mamba’s architecture is a unique blend of concepts from recurrent neural networks (RNNs), Transformers, and state space models. This hybrid approach allows Mamba to harness the strengths of each architecture while mitigating their weaknesses. The innovative selection mechanism within Mamba is particularly noteworthy; it parameterizes the state space model based on the input, enabling the model to dynamically adjust its focus on relevant information. This adaptability is crucial for handling diverse data types and maintaining performance across various tasks.

Mamba’s performance is a standout feature, demonstrating remarkable efficiency. It achieves up to three times faster computation on A100 GPUs compared to traditional Transformer models. This speedup is attributed to its ability to compute recurrently with a scanning method, which reduces the overhead associated with attention calculations. Moreover, Mamba’s near-linear scalability means that as the sequence length increases, the computational cost does not grow exponentially. This feature makes it feasible to process long sequences without incurring prohibitive resource demands, opening new avenues for deploying deep learning models in real-time applications.
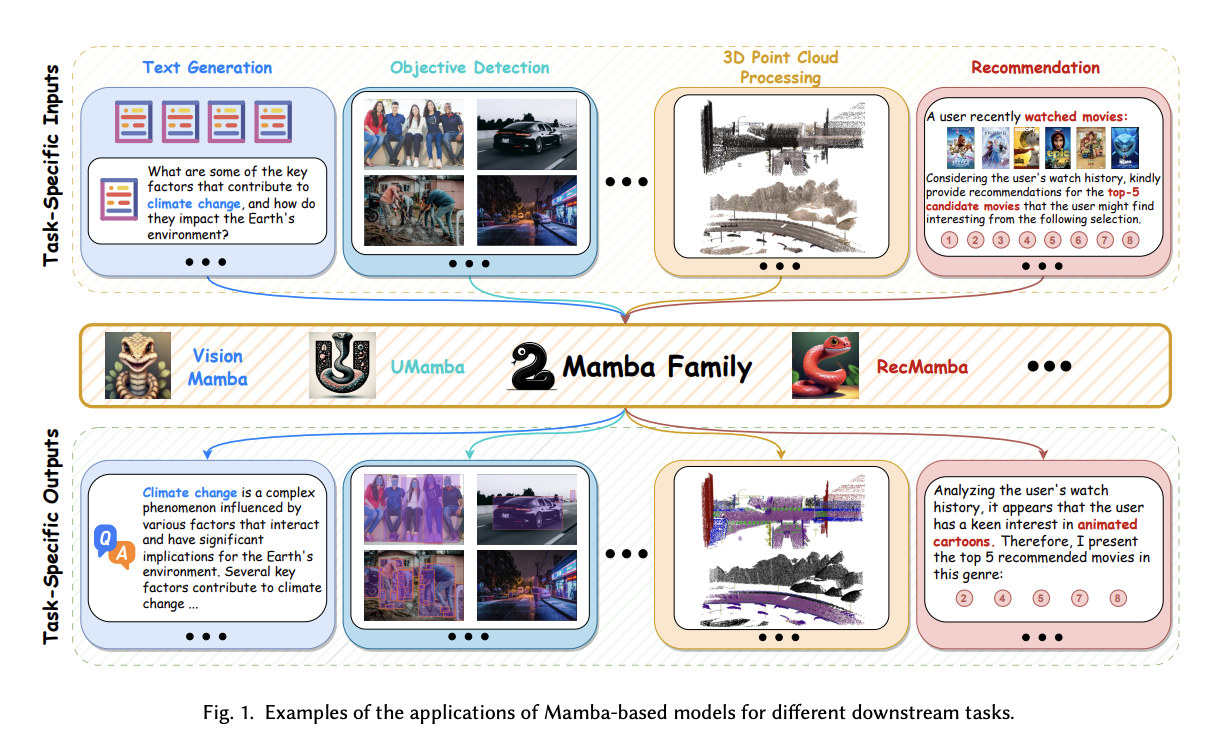
Moreover, Mamba’s architecture has been shown to retain powerful modeling capabilities for complex sequential data. By effectively capturing long-range dependencies and managing memory through its selection mechanism, Mamba can outperform traditional models in tasks requiring deep contextual understanding. This performance is particularly evident in applications such as text generation and image processing, where maintaining context over long sequences is paramount. As a result, Mamba stands out as a promising foundation model that not only addresses the limitations of Transformers but also paves the way for future advancements in deep learning applications across various domains.
This survey comprehensively reviews recent Mamba-associated studies, covering advancements in Mamba-based models, techniques for adapting Mamba to diverse data, and applications where Mamba can excel. Mamba’s powerful modeling capabilities for complex and lengthy sequential data and near-linear scalability make it a promising alternative to Transformers. The survey also discusses current limitations and explores promising research directions to provide deeper insights for future investigations. As Mamba continues to evolve, it holds great potential to significantly impact various fields and push the boundaries of deep learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.
[ad_2]
Source link