This AI Paper Explores How Vision-Language Models Enhance Autonomous Driving Systems for Better Decision-Making and Interactivity
[ad_1]
At the convergence of artificial intelligence, machine learning, and sensor technology, autonomous driving technology aims to develop vehicles that can comprehend their environment and make choices comparable to a human driver. This field focuses on creating systems that perceive, predict, and plan driving actions without human input, aiming to achieve higher safety and efficiency standards.
A primary obstacle in the development of self-driving vehicles is… developing systems capable of understanding and reacting to varied driving conditions as efficiently as human drivers. This involves processing complex sensory data and responding effectively to dynamic and often unforeseen situations, achieving decision-making and adaptability that closely matches human capabilities.
Traditional autonomous driving models have primarily relied on data-driven approaches, using machine learning trained on extensive datasets. These models directly translate sensor inputs into vehicle actions. However, they need to work on handling scenarios not covered in their training data, demonstrating a gap in their ability to generalize and adapt to new, unpredictable conditions.
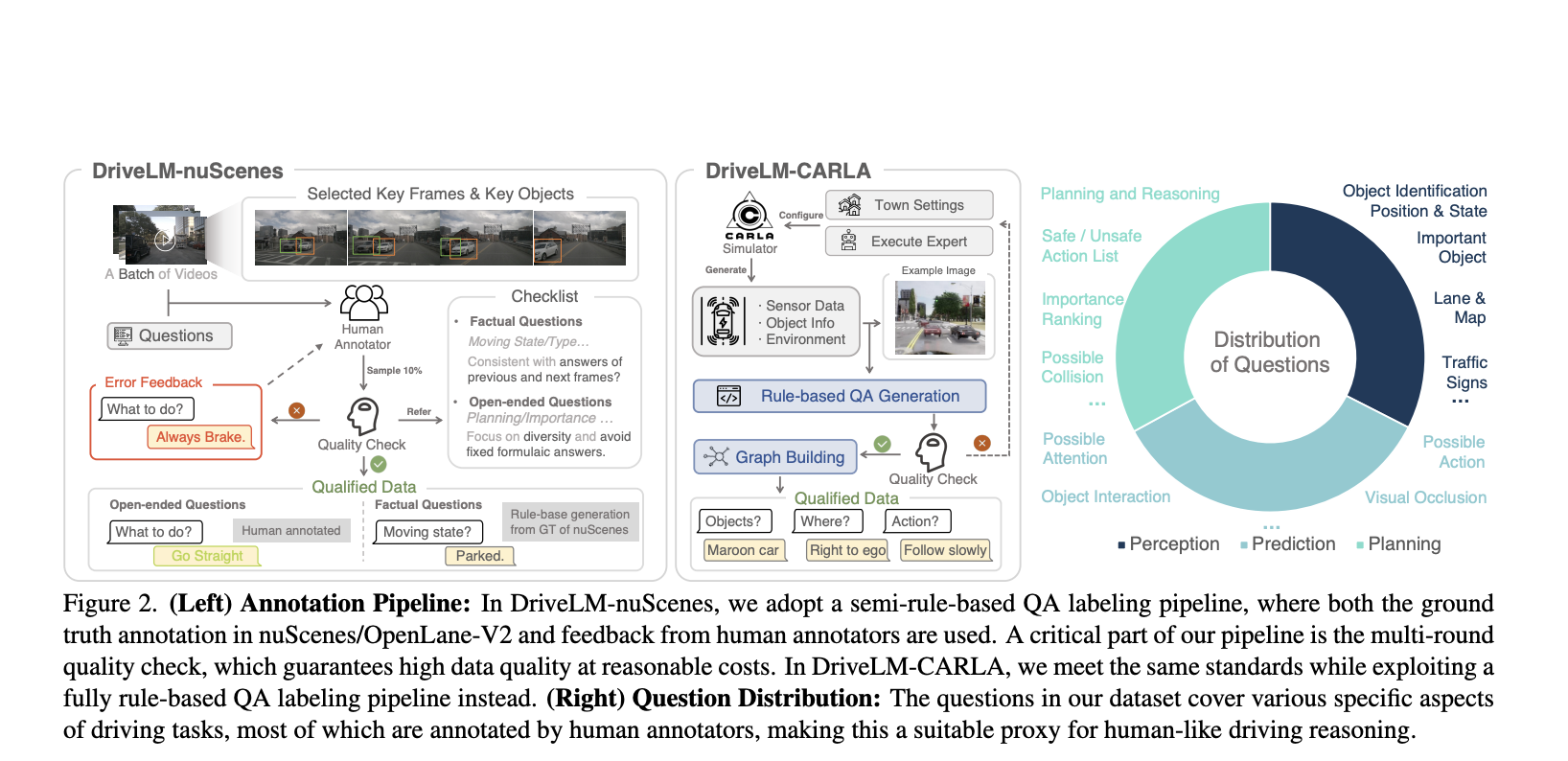
DriveLM introduces a novel approach to this challenge by employing Vision-Language Models (VLMs) specifically for autonomous driving. This model uses a graph-structured reasoning process integrating language-based interactions with visual inputs. This approach is designed to mimic human reasoning more closely than conventional models and is built upon general vision-language models like BLIP-2 for its simplicity and flexibility in architecture.

DriveLM is based on Graph Visual Question Answering (GVQA), which processes driving scenarios as interconnected question-answer pairs in a directed graph. This structure facilitates logical reasoning about the scene, a crucial component for decision-making in driving. The model employs the BLIP-2 VLM, fine-tuned on the DriveLM-nuScenes dataset, a collection with scene-level descriptions and frame-level question-answers designed to enable effective understanding and reasoning about driving scenarios. The ultimate goal of DriveLM is to translate an image into the desired vehicle motion through various VQA stages, encompassing perception, prediction, planning, behavior, and motion.
In terms of performance and results, DriveLM demonstrates remarkable generalization capabilities in handling complex driving scenarios. It shows a pronounced ability to adapt to unseen objects and sensor configurations not encountered during training. This adaptability represents a significant advancement over existing models, showcasing the potential of DriveLM in real-world driving situations.
DriveLM outperforms existing models in tasks that require understanding and reacting to new situations. Its graph-structured approach to reasoning about driving scenarios enables it to perform competitively compared to state-of-the-art driving-specific architectures. Moreover, DriveLM demonstrates promising baseline performance on P1-P3 question answering without context. However, the need for specialized architectures or prompting schemes beyond naive concatenation to better use the logical dependencies in GVQA is highlighted.
Overall, DriveLM represents a significant step forward in autonomous driving technology. By integrating language reasoning with visual perception, the model achieves better generalization and opens avenues for more interactive and human-friendly autonomous driving systems. This approach could potentially revolutionize the field, offering a model that understands and navigates complex driving environments with a perspective akin to human understanding and reasoning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
[ad_2]
Source link