This AI Paper Introduces a Verbalized Way to Perform Machine Learning and Conducts Several Case Studies on Regression and Classification Tasks

[ad_1]
Large Language Models (LLMs) have revolutionized problem-solving in machine learning, shifting the paradigm from traditional end-to-end training to utilizing pretrained models with carefully crafted prompts. This transition presents a fascinating dichotomy in optimization approaches. Conventional methods involve training neural networks from scratch using gradient descent in a continuous numerical space. In contrast, the emerging technique focuses on optimizing input prompts for LLMs in a discrete natural language space. This shift raises a compelling question: Can a pretrained LLM function as a system parameterized by its natural language prompt, analogous to how neural networks are parameterized by numerical weights? This new approach challenges researchers to rethink the fundamental nature of model optimization and adaptation in the era of large-scale language models.
Researchers have explored various applications of LLMs in planning, optimization, and multi-agent systems. LLMs have been employed for planning embodied agents’ actions and solving optimization problems by generating new solutions based on previous attempts and their associated losses. Natural language has also been utilized to enhance learning in various contexts, such as providing supervision for visual representation learning and creating zero-shot classification criteria for images.
Prompt engineering and optimization have emerged as crucial areas of study, with numerous methods developed to harness the reasoning capabilities of LLMs. Automatic prompt optimization techniques have been proposed to reduce the manual effort required in designing effective prompts. Also, LLMs have shown promise in multi-agent systems, where they can assume different roles to collaborate on complex tasks.
However, these existing approaches often focus on specific applications or optimization techniques without fully exploring the potential of LLMs as function approximators parameterized by natural language prompts. This limitation has left room for new frameworks that can bridge the gap between traditional machine learning paradigms and the unique capabilities of LLMs.
Researchers from the Max Planck Institute for Intelligent Systems, the University of Tübingen, and the University of Cambridge introduced the Verbal Machine Learning (VML) framework, a unique approach to machine learning by viewing LLMs as function approximators parameterized by their text prompts. This perspective draws an intriguing parallel between LLMs and general-purpose computers, where the functionality is defined by the running program or, in this case, the text prompt. The VML framework offers several advantages over traditional numerical machine learning approaches.
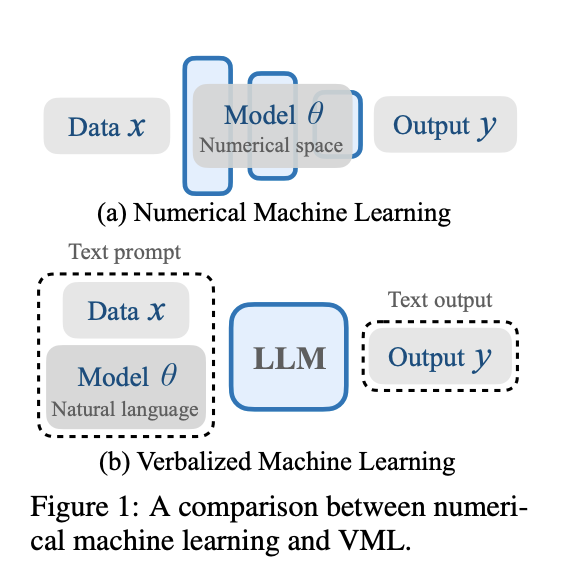
A key feature of VML is its strong interpretability. By using fully human-readable text prompts to characterize functions, the framework allows for easy understanding and tracing of model behavior and potential failures. This transparency is a significant improvement over the often opaque nature of traditional neural networks.
VML also presents a unified representation for both data and model parameters in a token-based format. This contrasts with numerical machine learning, which typically treats data and model parameters as distinct entities. The unified approach in VML potentially simplifies the learning process and provides a more coherent framework for handling various machine-learning tasks.

The results of the VML framework demonstrate its effectiveness across various machine-learning tasks, including regression, classification, and image analysis. Here’s a summary of the key findings:
VML shows promising performance in both simple and complex tasks. For linear regression, the framework accurately learns the underlying function, demonstrating its ability to approximate mathematical relationships. In more complex scenarios like sinusoidal regression, VML outperforms traditional neural networks, especially in extrapolation tasks, when provided with appropriate prior information.
In classification tasks, VML exhibits adaptability and interpretability. For linearly separable data (two-blob classification), the framework quickly learns an effective decision boundary. In non-linear cases (two circles classification), VML successfully incorporates prior knowledge to achieve accurate results. The framework’s ability to explain its decision-making process through natural language descriptions provides valuable insights into its learning progression.
VML’s performance in medical image classification (pneumonia detection from X-rays) highlights its potential in real-world applications. The framework shows improvement over training epochs and benefits from the inclusion of domain-specific prior knowledge. Notably, VML’s interpretable nature allows medical professionals to validate learned models, a crucial feature in sensitive domains.
Compared to prompt optimization methods, VML demonstrates a superior ability to learn detailed, data-driven insights. While prompt optimization often yields general descriptions, VML captures nuanced patterns and rules from the data, enhancing its predictive capabilities.
However, the results also reveal some limitations. VML exhibits a relatively large variance in training, partly due to the stochastic nature of language model inference. Also, numerical precision issues in language models can lead to fitting errors, even when the underlying symbolic expressions are correctly understood.
Despite these challenges, the overall results indicate that VML is a promising approach for performing machine learning tasks, offering interpretability, flexibility, and the ability to incorporate domain knowledge effectively.

This study introduces the VML framework, which demonstrates effectiveness in regression and classification tasks and validates language models as function approximators. VML excels in linear and nonlinear regression, adapts to various classification problems, and shows promise in medical image analysis. It outperforms traditional prompt optimization in learning detailed insights. However, limitations include high training variance due to LLM stochasticity, numerical precision errors affecting fitting accuracy, and scalability constraints from LLM context window limitations. These challenges present opportunities for future improvements to enhance VML’s potential as an interpretable and powerful machine-learning approach.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

[ad_2]
Source link