This AI Paper Presents A Comprehensive Study of Knowledge Editing for Large Language Models
[ad_1]
Recently, GPT-4 and other Large Language Models (LLMs) have demonstrated an impressive capacity for Natural Language Processing (NLP) to memorize extensive amounts of information, possibly even more so than humans. The success of LLMs in dealing with massive amounts of data has led to the development of models of the generative processes that are more brief, coherent, and interpretable—a “world model,” if you will.
Additional insights are gained from LLMs’ capacity to comprehend and control intricate strategic contexts; for example, previous research has shown that transformers trained to predict the next token in board games like Othello create detailed models of the current game state. Researchers have discovered the ability of LLMs to learn representations that reflect perceptual and symbolic notions and track subjects’ boolean states within certain situations. With this two-pronged capability, LLMs can store massive amounts of data and organize it in ways that mimic human thought processes, making them ideal knowledge bases.
Factual fallacies, the possibility of creating harmful content, and out-of-date information are some of the limitations of LLMs due to their training limits. It will take time and money to retrain everyone to fix these problems. In response, there has been a proliferation of LLM-centric knowledge editing approaches in recent years, allowing for efficient, on-the-fly model tweaks. Understanding how LLMs display and process information is critical for guaranteeing the fairness and safety of Artificial Intelligence (AI) systems; this technique focuses on specific areas for change without affecting overall performance. The primary goal of this work is to survey the history and current state of knowledge editing for LLMs.
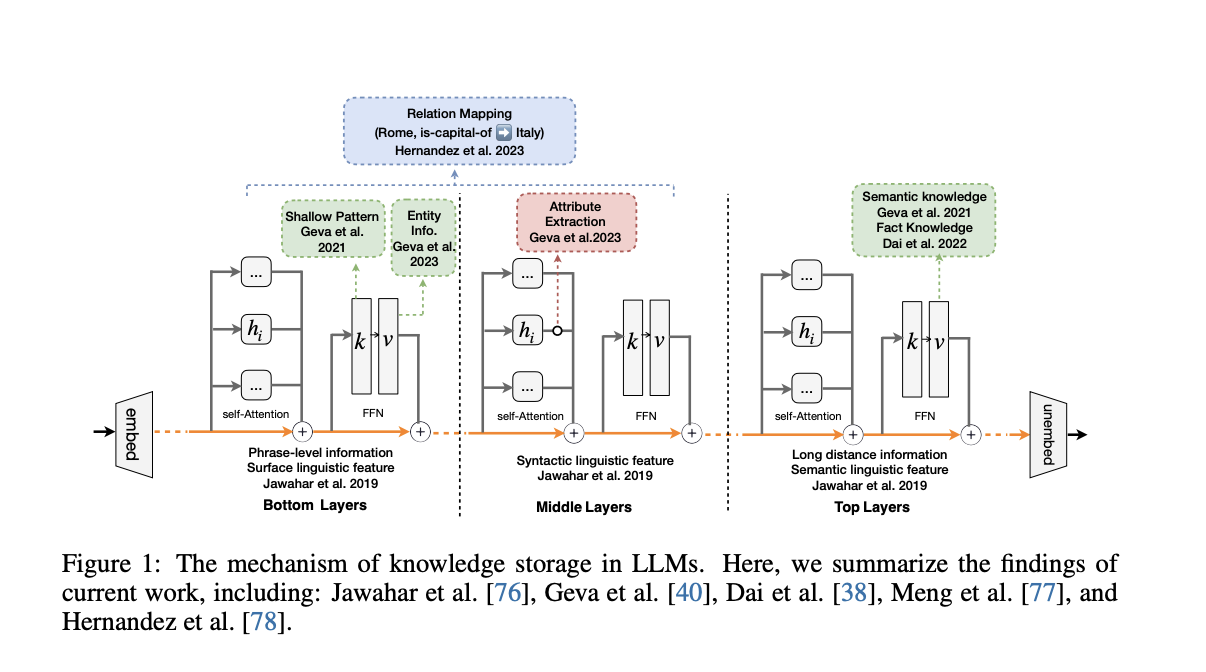
New research by a team of researchers from Zhejiang University, the National University of Singapore, the University of California, Ant Group, and Alibaba Group provides the initial step to provide an overview of Transformers’ design, the way LLMs store knowledge, and related approaches such as parameter-efficient fine-tuning, knowledge augmentation, continuing learning, and machine unlearning. After that, the team lays out the groundwork, officially defines the knowledge editing problem, and provides a new taxonomy that brings together theories from education and cognitive science to offer a coherent perspective on knowledge editing techniques. In particular, they classify knowledge editing strategies for LLMs as follows: editing internal knowledge methods, merging knowledge into the model, and resorting to external knowledge.
The researchers present their classification criteria in their paper as follows:
- Drawing on Information from Other Sources: This method is analogous to the recognition phase of human cognition, which, upon initial encounter with new information, requires exposure to the information within an appropriate context.
- Integrating Experiential Data Into The Model: By drawing parallels between the incoming information and the model’s current knowledge, this method is similar to the association phase in human cognitive processes. A learned knowledge representation would be combined with or used in place of the output or intermediate output by the methods.
- Revising Inherent Information: Revising knowledge in this way is similar to going through the “mastery phase” of learning something new. It entails the model consistently using LLM weight modifications to incorporate knowledge into its parameters.
Subsequently, twelve natural language processing datasets are subjected to thorough experiments in this article. The performance, usability, underlying mechanisms, and other issues are carefully considered in their design.
To provide a fair comparison and show how well these methods work in information insertion, modification, and erasure settings, the researchers build a new benchmark called KnowEdit and describe the empirical results of state-of-the-art LLM knowledge editing techniques.
The researchers demonstrate how knowledge editing affects both general tasks and multi-task knowledge editing, suggesting that modern methods of knowledge editing successfully update facts with little impact on the model’s cognitive abilities and adaptability in different knowledge domains. In altered LLMs, they find that one or more columns in the value layer are heavily focused. It has been suggested that LLMs may be retrieving answers by retrieving information from their pre-training corpus or through a multi-step reasoning process.
The findings suggest that knowledge-locating processes, such as causal analysis, focus on areas related to the entity in question rather than the entire factual context. Furthermore, the team also explores the potential for knowledge editing for LLMs to have unforeseen repercussions, which is an important element to think about thoroughly.
Lastly, they explore the vast array of uses for knowledge editing, looking at its possibilities from several angles. These uses include trustworthy AI, efficient machine learning, AI-generated content (AIGC), and individualized agents in human-computer interaction. The researchers hope this study may spark new lines of inquiry into LLMs with an eye toward efficiency and creativity. They have released all of their resources—including codes, data splits, and trained model checkpoints—to the public to facilitate and inspire more study.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
[ad_2]
Source link